

{kind=link}
We’re saying the general public preview of Fireworks AI on Microsoft Foundry, bringing excessive‑efficiency open mannequin inference into Azure. This integration displays Microsoft Foundry’s broader path: offering a single place the place builders cannot solely run open fashions effectively but additionally customise and operationalize them as a part of an entire enterprise‑prepared AI lifecycle.
Throughout industries, organizations are more and more standardizing on open fashions to achieve better management over efficiency, price, customization, and the safety and compliance required for enterprise deployment. Open fashions give groups the pliability to decide on the proper structure for every workload and keep away from lock‑in to a single mannequin supplier as their wants evolve.
As adoption grows, nevertheless, efficiency alone is not sufficient. Groups want a constant technique to consider fashions shortly, function them safely in manufacturing, and enhance them over time with out rebuilding infrastructure or fragmenting their tooling. Too usually, organizations are compelled to assemble bespoke serving stacks, slowing innovation and making it more durable to scale and compound progress.
Microsoft Foundry is designed to deal with this problem. It serves as a unified system of file and enterprise management airplane for AI, bringing collectively fashions, brokers, analysis, deployment, and governance right into a single expertise. With Microsoft Foundry, groups can transfer from experimentation to manufacturing with confidence, utilizing the fashions and frameworks that greatest match their necessities, whereas counting on a constant operational basis.
Immediately, we’re saying the general public preview of Fireworks AI on Microsoft Foundrybringing excessive‑efficiency open mannequin inference into Azure. This integration displays Microsoft Foundry’s broader path: offering a single place the place builders cannot solely run open fashions effectively but additionally customise and operationalize them as a part of an entire enterprise‑prepared AI lifecycle.
Fireworks AI fashions on Microsoft Foundry: A single place for open fashions
Fireworks AI delivers industry-leading inference for open fashions, and Microsoft Foundry is what makes that efficiency usable at enterprise scale. Accessing Fireworks AI by way of Microsoft Foundry provides groups a single, trusted management airplane to guage, deploy, customise, and function open fashions alongside the remainder of their AI stack.
As open fashions mature, customization more and more extends past coaching. Groups want constant methods to configure, deploy, optimize, govern, and iterate on fashions in manufacturing with out fragmenting instruments or infrastructure. Microsoft Foundry gives the setting the place these customization and operational workflows are standardized, whereas Fireworks AI provides the efficiency and effectivity wanted to run open fashions at scale. This implies groups can transfer from experimentation to manufacturing utilizing open fashions with out stitching collectively separate instruments, contracts, and deployment paths.
Collectively, Fireworks AI and Microsoft Foundry allow a extra full and sustainable method to working with open fashions combining quick, environment friendly inference with a platform designed to help enterprise open mannequin operations over time.
With Fireworks AI on Foundry, builders can get entry to best-in-class inferencing for open fashionstogether with optimized deployments for customized weight fashions. Fireworks AI is a market chief for top efficiency inference for open fashions. Its engine already runs at web scale processing over 13T tokens day by day, sustaining about 180 thousand requests per second, and producing over 1,000 tokens per second on massive fashions, substantiated by main benchmark efficiency on Synthetic Evaluation. This efficiency is now out there on Foundry.
Builders can log into Foundry and entry these open fashions with Fireworks AI at present:
- DeepSeek V3.2
- OpenAI gpt-oss-120b
- Like K2.5
- MiniMax M2.5 (new)
This brings a brand new open mannequin (MiniMax M2.5) to Foundry with serverless help and gives optimized inference for already standard open fashions.
With Fireworks AI in Microsoft Foundry, builders can:
- Consider fashions sooner with day‑zero entry and help: Begin constructing instantly with entry to state-of-the-art open fashions from Fireworks AI by way of a single Azure endpoint through Foundry.
- Optimize inference: Requests to open fashions are served by Fireworks’ excessive‑throughput inference stack for quick efficiency with Azure‑grade governance.
- Run the fashions you already belief: With bring-your-own-weights (BYOW), you possibly can add and register quantized or tremendous‑tuned weights educated elsewhere with out altering the serving stack.
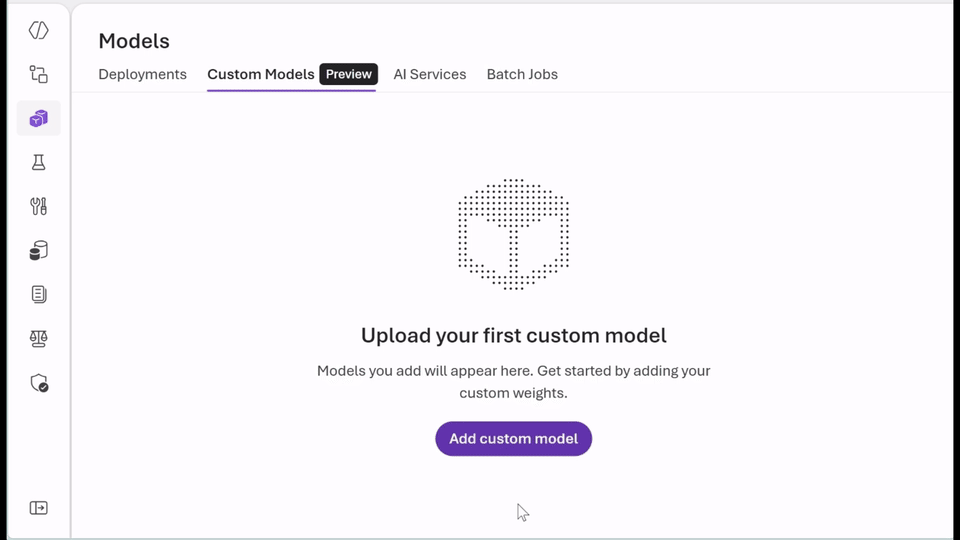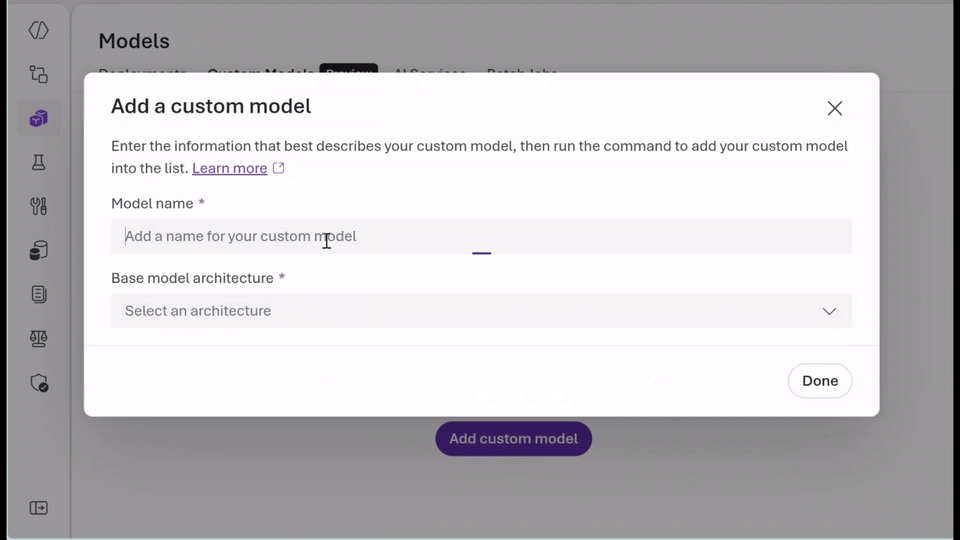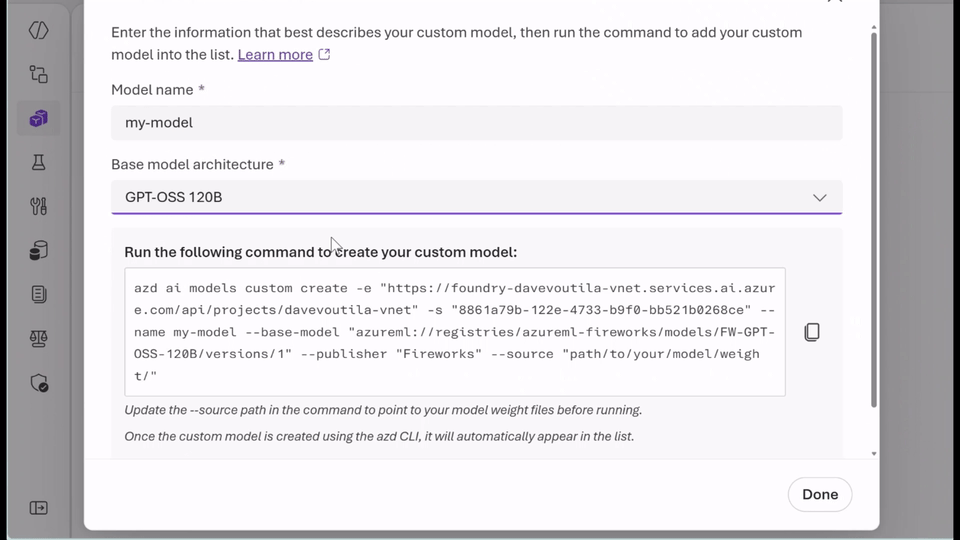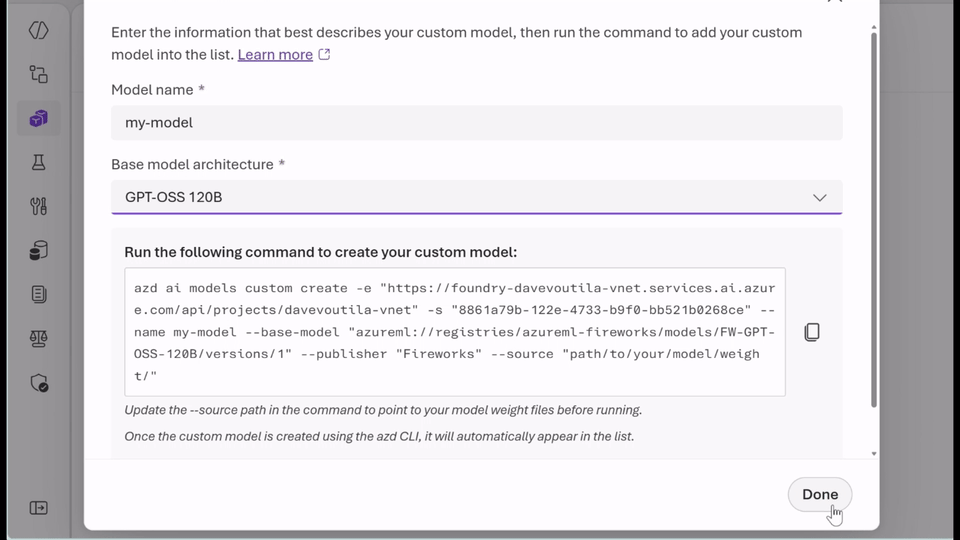
- Select the proper pricing mannequin in your workload: Use serverless, pay-per‑token inference to experiment securely and shortly with Knowledge Zone Normal or select provisioned throughput items (PTUs) for predictable, steady-state efficiency with base or customized fashions. Whether or not you’re optimizing for agility or effectivity, you get flexibility with out managing infrastructure.
- Function with enterprise belief and scale: We’re dedicated to enabling clients to construct production-ready AI functions shortly, whereas sustaining the best ranges of security and safety. Foundry gives an end-to-end workspace for agent improvement, analysis, and deployment, together with unified governance, observability, and agent-ready tooling.
The way forward for Fireworks and AI use circumstances
Microsoft Foundry is evolving to help the complete lifecycle of open fashions—from early analysis by way of manufacturing operation and ongoing optimization. As groups scale their use of open fashions, having a constant, enterprise‑prepared basis turns into more and more necessary.
By integrating Fireworks AI into Microsoft Foundry, builders achieve entry to excessive‑efficiency inference at present whereas constructing on a platform designed to help deeper customization and enterprise operations over time. This method provides groups the boldness to undertake open fashions not only for what they will do now, however for the way they will develop, adapt, and function reliably as their AI ambitions increase. We’re trying ahead to seeing how builders and enterprises use Fireworks AI on Microsoft Foundry to energy the following technology of clever functions.
To get began:
- Go to Microsoft Foundry fashions and choose Fireworks AI open fashions within the mannequin catalog assortment.
- Choose the open mannequin hosted by Fireworks.
- View the mannequin card.
- Choose your deployment choice—serverless or PTU—and deploy.