

{kind=link}
On this article, you’ll learn the way inference caching works in massive language fashions and how one can use it to scale back price and latency in manufacturing techniques.
Subjects we are going to cowl embody:
- The basics of inference caching and why it issues
- The three foremost caching varieties: KV caching, prefix caching, and semantic caching
- How to decide on and mix caching methods in real-world purposes
The Full Information to Inference Caching in LLMs
Picture by Writer
Introduction
Calling a big language mannequin API at scale is dear and sluggish. A big share of that price comes from repeated computation: the identical system immediate processed from scratch on each request, and the identical frequent queries answered as if the mannequin has by no means seen them earlier than. Inference caching addresses this by storing the outcomes of costly LLM computations and reusing them when an equal request arrives.
Relying on which caching layer you apply, you possibly can skip redundant consideration computation mid-request, keep away from reprocessing shared immediate prefixes throughout requests, or serve frequent queries from a lookup with out invoking the mannequin in any respect. In manufacturing techniques, this could considerably scale back token spend with virtually no change to utility logic.
This text covers:
- What inference caching is and why it issues
- The three foremost caching varieties: key-value (KV), prefix, and semantic caching
- How semantic caching extends protection past precise prefix matches
Every part builds towards a sensible choice framework for selecting the best caching technique in your utility.
What Is Inference Caching?
Once you ship a immediate to a big language mannequin, the mannequin performs a considerable quantity of computation to course of the enter and generate every output token. That computation takes time and prices cash. Inference caching is the observe of storing the outcomes of that computation — at numerous ranges of granularity — and reusing them when an analogous or equivalent request arrives.
There are three distinct varieties to grasp, every working at a unique layer of the stack:
- KV caching: Caches the inner consideration states — key-value pairs — computed throughout a single inference request, so the mannequin doesn’t recompute them at each decode step. This occurs mechanically contained in the mannequin and is at all times on.
- Prefix caching: Extends KV caching throughout a number of requests. When completely different requests share the identical main tokens, comparable to a system immediate, a reference doc, or few-shot examples, the KV states for that shared prefix are saved and reused throughout all of them. You might also see this referred to as immediate caching or context caching.
- Semantic caching: A better-level, application-side cache that shops full LLM enter/output pairs and retrieves them based mostly on semantic similarity. Not like prefix caching, which operates on consideration states mid-computation, semantic caching short-circuits the mannequin name totally when a sufficiently related question has been seen earlier than.
These usually are not interchangeable options. They’re complementary layers. KV caching is at all times working. Prefix caching is the highest-leverage optimization you possibly can add to most manufacturing purposes. Semantic caching is an extra enhancement when question quantity and similarity are excessive sufficient to justify it.
Understanding How KV Caching Works
KV caching is the inspiration that every little thing else builds on. To grasp it, you want a quick have a look at how transformer consideration works throughout inference.
The Consideration Mechanism and Its Value
Fashionable LLMs use the transformer structure with self-attention. For each token within the enter, the mannequin computes three vectors:
- Q (Question) — What is that this token searching for?
- Okay (Key) — What does this token provide to different tokens?
- V (Worth) — What data does this token carry?
Consideration scores are computed by evaluating every token’s question towards the keys of all earlier tokens, then utilizing these scores to weight the values. This enables the mannequin to grasp context throughout the total sequence.
LLMs generate output autoregressively — one token at a time. With out caching, producing token N would require recomputing Okay and V for all N-1 earlier tokens from scratch. For lengthy sequences, this price compounds with each decode step.
How KV Caching Fixes This
Throughout a ahead move, as soon as the mannequin computes the Okay and V vectors for a token, these values are saved in GPU reminiscence. For every subsequent decode step, the mannequin seems up the saved Okay and V pairs for the present tokens fairly than recomputing them. Solely the newly generated token requires contemporary computation. Right here is a straightforward instance:
|
With out KV caching (producing token 100): Recompute Okay, V for tokens 1–99 → then compute token 100 With KV caching (producing token 100): Load saved Okay, V for tokens 1–99 → compute token 100 solely |
That is KV caching in its authentic sense: an optimization inside a single request. It’s computerized and common; each LLM inference framework permits it by default. You don’t want to configure it. Nonetheless, understanding it’s important for understanding prefix caching, which extends this mechanism throughout requests.
For a extra thorough clarification, see KV Caching in LLMs: A Information for Builders.
Utilizing Prefix Caching to Reuse KV States Throughout Requests
Prefix caching — additionally referred to as immediate caching or context caching relying on the supplier — takes the KV caching idea one step additional. As an alternative of caching consideration states solely inside a single request, it caches them throughout a number of requests — particularly for any shared prefix these requests have in frequent.
The Core Concept
Think about a typical manufacturing LLM utility. You’ve got a protracted system immediate — directions, a reference doc, and few-shot examples — that’s equivalent throughout each request. Solely the person’s message on the finish modifications. With out prefix caching, the mannequin recomputes the KV states for that total system immediate on each name. With prefix caching, it computes them as soon as, shops them, and each subsequent request that shares that prefix skips on to processing the person’s message.
The Onerous Requirement: Precise Prefix Match
Prefix caching solely works when the cached portion of the immediate is byte-for-byte equivalent. A single character distinction — a trailing area, a modified punctuation mark, or a reformatted date — invalidates the cache and forces a full recomputation. This has direct implications for a way you construction your prompts.
Place static content material first and dynamic content material final. System directions, reference paperwork, and few-shot examples ought to lead each immediate. Per-request variables — the person’s message, a session ID, or the present date — ought to seem on the finish.
Equally, keep away from non-deterministic serialization. For those who inject a JSON object into your immediate and the important thing order varies between requests, the cache won’t ever hit, even when the underlying knowledge is equivalent.
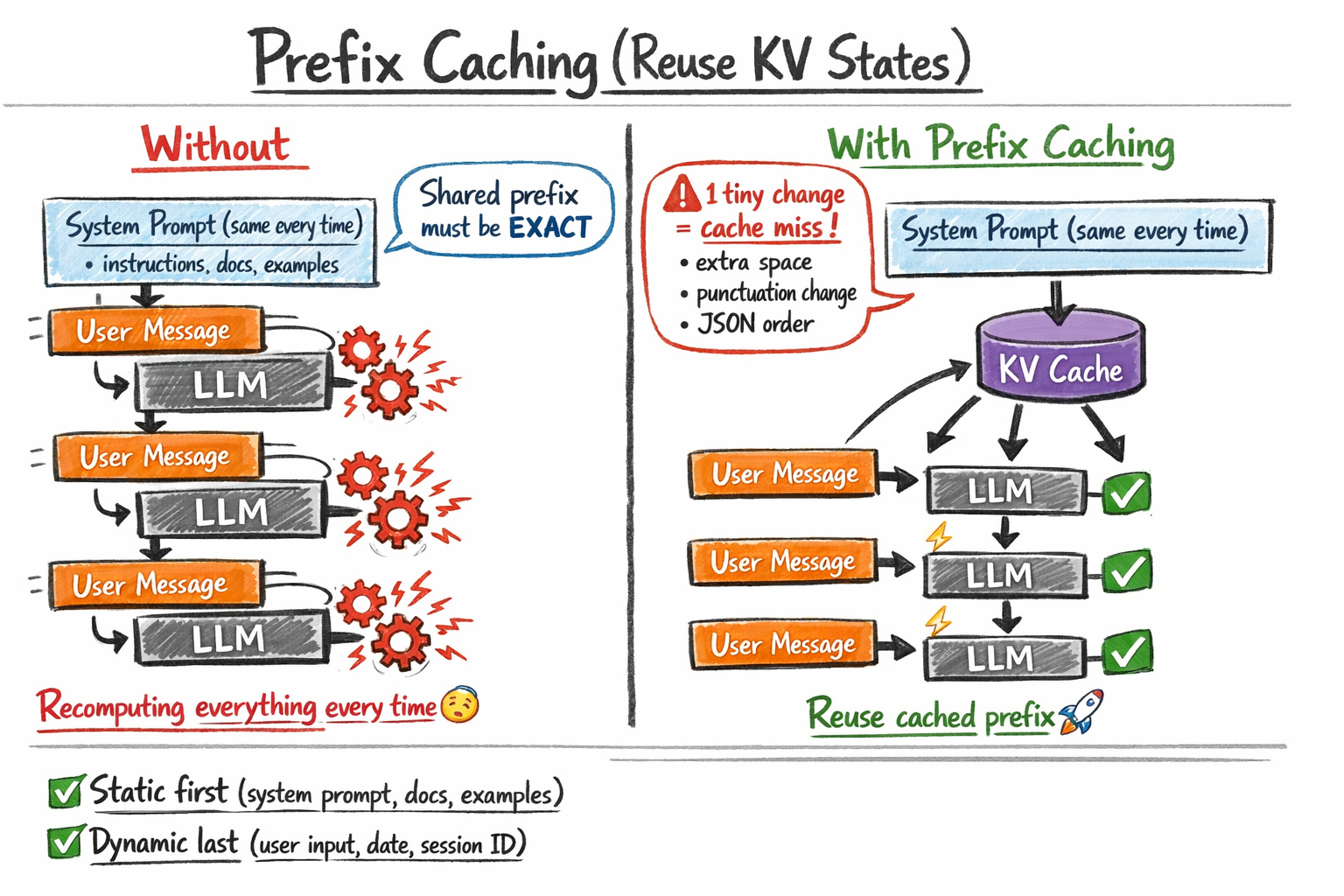
How prefix caching works
Supplier Implementations
A number of main API suppliers expose prefix caching as a first-class characteristic.
Anthropic calls it immediate caching. You choose in by including a cache_control parameter to the content material blocks you need cached. OpenAI applies prefix caching mechanically for prompts longer than 1024 tokens. The identical structural rule applies: the cached portion should be the steady main prefix of your immediate.
Google Gemini calls it context caching and prices for saved cache individually from inference. This makes it most cost-effective for very massive, steady contexts which can be reused many occasions throughout requests.
Open-source frameworks like vLLM and SGLang assist computerized prefix caching for self-hosted fashions, managed transparently by the inference engine with none modifications to your utility code.
Understanding How Semantic Caching Works
Semantic caching operates at a unique layer: it shops full LLM enter/output pairs and retrieves them based mostly on that means, not precise token matches.
The sensible distinction is critical. Prefix caching makes processing a protracted shared system immediate cheaper on each request. Semantic caching skips the mannequin name totally when a semantically equal question has already been answered, no matter whether or not the precise wording matches.
Right here is how semantic caching works in observe:
- A brand new question arrives. Compute its embedding vector.
- Search a vector retailer for cached entries whose question embeddings exceed a cosine similarity threshold.
- If a match is discovered, return the cached response straight with out calling the mannequin.
- If no match is discovered, name the LLM, retailer the question embedding and response within the cache, and return the consequence.
In manufacturing, you should utilize vector databases comparable to Pinecone, Weaviate, or pgvector, and apply an acceptable TTL so stale cached responses don’t persist indefinitely.
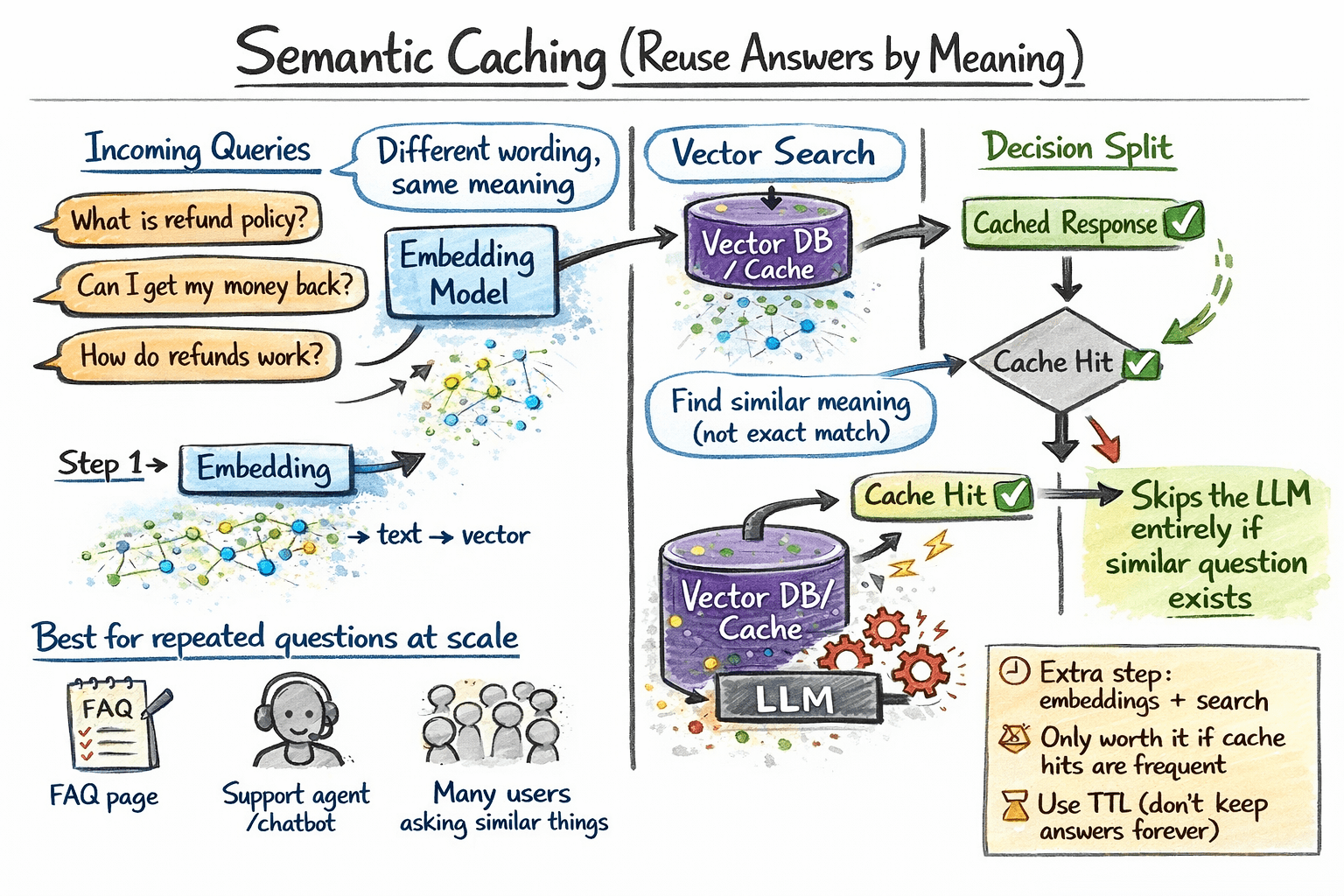
How semantic caching works
When Semantic Caching Is Definitely worth the Overhead
Semantic caching provides an embedding step and a vector search to each request. That overhead solely pays off when your utility has enough question quantity and repeated questions such that the cache hit price justifies the added latency and infrastructure. It really works greatest for FAQ-style purposes, buyer assist bots, and techniques the place customers ask the identical questions in barely alternative ways at excessive quantity.
Selecting The Proper Caching Technique
These three varieties function at completely different layers and clear up completely different issues.
| USE CASE | CACHING STRATEGY |
|---|---|
| All purposes, at all times | KV caching (computerized, nothing to configure) |
| Lengthy system immediate shared throughout many customers | Prefix caching |
| RAG pipeline with massive shared reference paperwork | Prefix caching for the doc block |
| Agent workflows with massive, steady context | Prefix caching |
| Excessive-volume utility the place customers paraphrase the identical questions | Semantic caching |
The simplest manufacturing techniques layer these methods. KV caching is at all times working beneath. Add prefix caching in your system immediate — that is the highest-leverage change for many purposes. Layer semantic caching on high in case your question patterns and quantity justify the extra infrastructure.
Conclusion
Inference caching isn’t a single approach. It’s a set of complementary instruments that function at completely different layers of the stack:
- KV caching runs mechanically contained in the mannequin on each request, eliminating redundant consideration recomputation throughout the decode stage.
- Prefix caching, additionally referred to as immediate caching or context caching, extends KV caching throughout requests so a shared system immediate or doc is processed as soon as, no matter what number of customers entry it.
- Semantic caching sits on the utility layer and short-circuits the mannequin name totally for semantically equal queries.
For many manufacturing purposes, the primary and highest-leverage step is enabling prefix caching in your system immediate. From there, add semantic caching in case your utility has the question quantity and person patterns to make it worthwhile.
As a concluding be aware, inference caching stands out as a sensible approach to enhance massive language mannequin efficiency whereas lowering prices and latency. Throughout the completely different caching methods mentioned, the frequent theme is avoiding redundant computation by storing and retrieving prior outcomes the place attainable. When utilized thoughtfully — with consideration to cache design, invalidation, and relevance — these methods can considerably improve system effectivity with out compromising output high quality.