

{kind=link}
People excel at processing huge arrays of visible info, a ability that’s essential for reaching synthetic basic intelligence (AGI). Over the a long time, AI researchers have developed Visible Query Answering (VQA) techniques to interpret scenes inside single photographs and reply associated questions. Whereas current developments in basis fashions have considerably closed the hole between human and machine visible processing, typical VQA has been restricted to purpose about solely single photographs at a time slightly than entire collections of visible knowledge.
This limitation poses challenges in additional complicated situations. Take, for instance, the challenges of discerning patterns in collections of medical photographs, monitoring deforestation via satellite tv for pc imagery, mapping city adjustments utilizing autonomous navigation knowledge, analyzing thematic parts throughout massive artwork collections, or understanding client habits from retail surveillance footage. Every of those situations entails not solely visible processing throughout tons of or 1000’s of photographs but additionally necessitates cross-image processing of those findings. To deal with this hole, this challenge focuses on the “Multi-Picture Query Answering” (MIQA) process, which exceeds the attain of conventional VQA techniques.
Visible Haystacks: the primary “visual-centric” Needle-In-A-Haystack (NIAH) benchmark designed to scrupulously consider Massive Multimodal Fashions (LMMs) in processing long-context visible info.
The way to Benchmark VQA Fashions on MIQA?
The “Needle-In-A-Haystack” (NIAH) problem has just lately grow to be some of the well-liked paradigms for benchmarking LLM’s capacity to course of inputs containing “lengthy contexts”, massive units of enter knowledge (similar to lengthy paperwork, movies, or tons of of photographs). On this process, important info (“the needle”), which comprises the reply to a selected query, is embedded inside an enormous quantity of information (“the haystack”). The system should then retrieve the related info and reply the query appropriately.
The primary NIAH benchmark for visible reasoning was launched by Google within the Gemini-v1.5 technical report. On this report, they requested their fashions to retrieve textual content overlaid on a single body in a big video. It seems that present fashions carry out fairly nicely on this process—primarily as a consequence of their sturdy OCR retrieval capabilities. However what if we ask extra visible questions? Do fashions nonetheless carry out as nicely?
What’s the Visible Haystacks (VHs) Benchmark?
In pursuit of evaluating “visual-centric” long-context reasoning capabilities, we introduce the “Visible Haystacks (VHs)” benchmark. This new benchmark is designed to evaluate Massive Multimodal Fashions (LMMs) in visible retrieval and reasoning throughout massive uncorrelated picture units. VHs options roughly 1K binary question-answer pairs, with every set containing anyplace from 1 to 10K photographs. In contrast to earlier benchmarks that centered on textual retrieval and reasoning, VHs questions heart on figuring out the presence of particular visible content material, similar to objects, using photographs and annotations from the COCO dataset.
The VHs benchmark is split into two fundamental challenges, every designed to check the mannequin’s capacity to precisely find and analyze related photographs earlier than responding to queries. We have now fastidiously designed the dataset to make sure that guessing or counting on frequent sense reasoning with out viewing the picture gained’t get any benefits (i.e., leading to a 50% accuracy price on a binary QA process).
-
Single-Needle Problem: Solely a single needle picture exists within the haystack of photographs. The query is framed as, “For the picture with the anchor object, is there a goal object?”
-
Multi-Needle Problem: Two to 5 needle photographs exist within the haystack of photographs. The query is framed as both, “For all photographs with the anchor object, do all of them include the goal object?” or “For all photographs with the anchor object, do any of them include the goal object?”
Three Necessary Findings from VHs
The Visible Haystacks (VHs) benchmark reveals important challenges confronted by present Massive Multimodal Fashions (LMMs) when processing intensive visible inputs. In our experiments throughout each single and multi-needle modes, we evaluated a number of open-source and proprietary strategies together with LLaVA-v1.5, GPT-4o, Claude-3 Opus, and Gemini-v1.5-pro. Moreover, we embrace a “Captioning” baseline, using a two-stage method the place photographs are initially captioned utilizing LLaVA, adopted by answering the query utilizing the captions’ textual content content material with Llama3. Beneath are three pivotal insights:
-
Struggles with Visible Distractors
In single-needle settings, a notable decline in efficiency was noticed because the variety of photographs elevated, regardless of sustaining excessive oracle accuracy—a state of affairs absent in prior text-based Gemini-style benchmarks. This exhibits that present fashions might primarily battle with visible retrieval, particularly within the presence of difficult visible distractors. Moreover, it’s essential to focus on the constraints on open-source LMMs like LLaVA, which might deal with solely as much as three photographs as a consequence of a 2K context size restrict. Then again, proprietary fashions similar to Gemini-v1.5 and GPT-4o, regardless of their claims of prolonged context capabilities, usually fail to handle requests when the picture depend exceeds 1K, as a consequence of payload measurement limits when utilizing the API name.
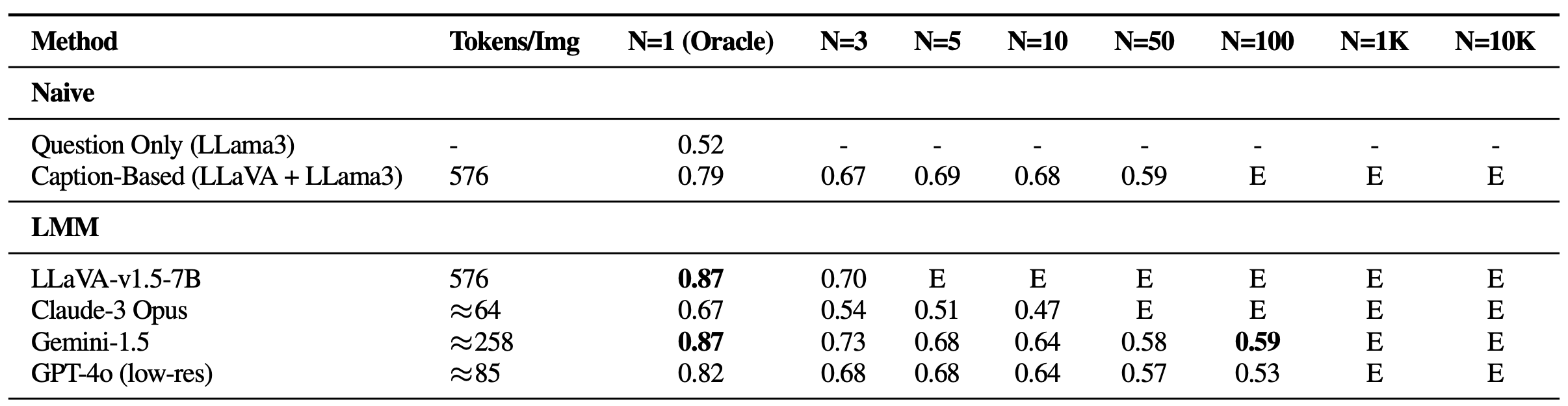
Efficiency on VHs for single-needle questions. All fashions expertise important falloff as the dimensions of the haystack (N) will increase, suggesting none of them are strong towards visible distractors. E: Exceeds context size. -
Problem Reasoning Throughout A number of Photographs
Apparently, all LMM-based strategies confirmed weak efficiency with 5+ photographs in single-image QA and all multi-needle settings in comparison with a primary method chaining a captioning mannequin (LLaVA) with an LLM aggregator (Llama3). This discrepancy means that whereas LLMs are able to integrating long-context captions successfully, present LMM-based options are insufficient for processing and integrating info throughout a number of photographs. Notably, the efficiency massively deteriorates in multi-image situations, with Claude-3 Opus exhibiting weak outcomes with solely oracle photographs, and Gemini-1.5/GPT-4o dropping to 50% accuracy (similar to a random guess) with bigger units of fifty photographs.

Outcomes on VHs for multi-needle questions. All visually-aware fashions carry out poorly, indicating that fashions discover it difficult to implicitly combine visible info. -
Phenomena in Visible Area
Lastly, we discovered that the accuracy of LMMs is massively affected by the place of the needle picture inside the enter sequence. As an example, LLaVA exhibits higher efficiency when the needle picture is positioned instantly earlier than the query, struggling as much as a 26.5% drop in any other case. In distinction, proprietary fashions usually carry out higher when the picture is positioned firstly, experiencing as much as a 28.5% lower when not. This sample echoes the “lost-in-the-middle” phenomenon seen within the subject of Pure Language Processing (NLP), the place essential info positioned at the start or finish of the context influences mannequin efficiency. This challenge was not evident in earlier Gemini-style NIAH analysis, which solely required textual content retrieval and reasoning, underscoring the distinctive challenges posed by our VHs benchmark.
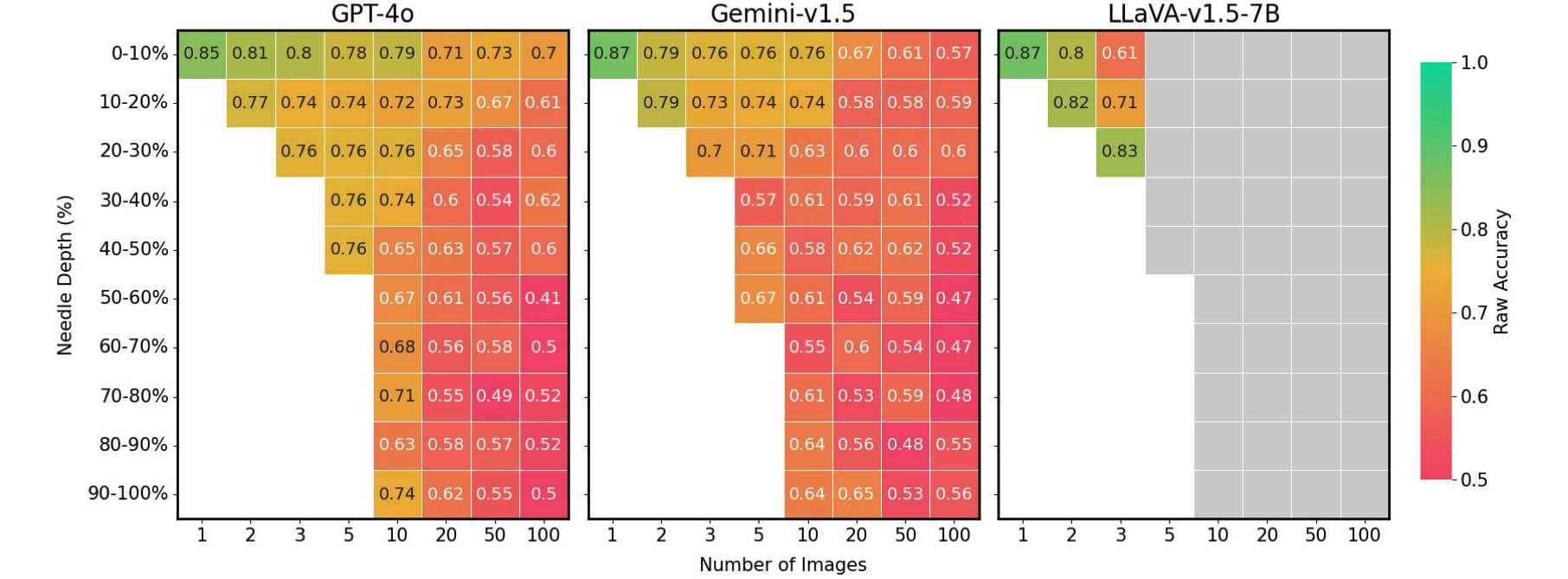
Needle place vs. efficiency on VHs for numerous picture settings. Present LMMs present as much as 41% efficiency drop when the needle will not be ideally positioned. Grey containers: Exceeds context size.
MIRAGE: A RAG-based Resolution for Improved VHs Efficiency
Primarily based on the experimental outcomes above, it’s clear that the core challenges of present options in MIQA lie within the capacity to (1) precisely retrieve related photographs from an enormous pool of probably unrelated photographs with out positional biases and (2) combine related visible info from these photographs to appropriately reply the query. To deal with these points, we introduce an open-source and easy single-stage coaching paradigm, “MIRAGE” (Multi-Picture Retrieval Augmented Technology), which extends the LLaVA mannequin to deal with MIQA duties. The picture beneath exhibits our mannequin structure.
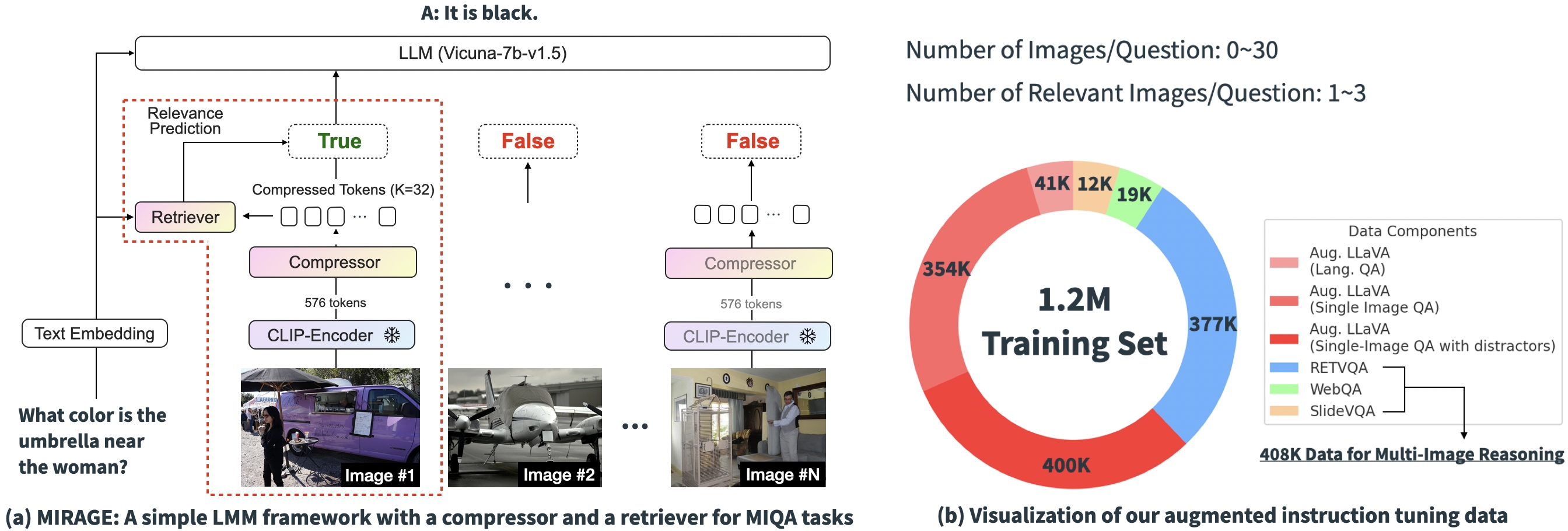
Our proposed paradigm consists of a number of elements, every designed to alleviate key points within the MIQA process:
-
Compress present encodings: The MIRAGE paradigm leverages a query-aware compression mannequin to cut back the visible encoder tokens to a smaller subset (10x smaller), permitting for extra photographs in the identical context size.
-
Make use of retriever to filter out irrelevant message: MIRAGE makes use of a retriever educated in-line with the LLM fine-tuning, to foretell if a picture can be related, and dynamically drop irrelevant photographs.
-
Multi-Picture Coaching Knowledge: MIRAGE augments present single-image instruction fine-tuning knowledge with multi-image reasoning knowledge, and artificial multi-image reasoning knowledge.
Outcomes
We revisit the VHs benchmark with MIRAGE. Along with being able to dealing with 1K or 10K photographs, MIRAGE achieves state-of-the-art efficiency on most single-needle duties, regardless of having a weaker single-image QA spine with solely 32 tokens per picture!
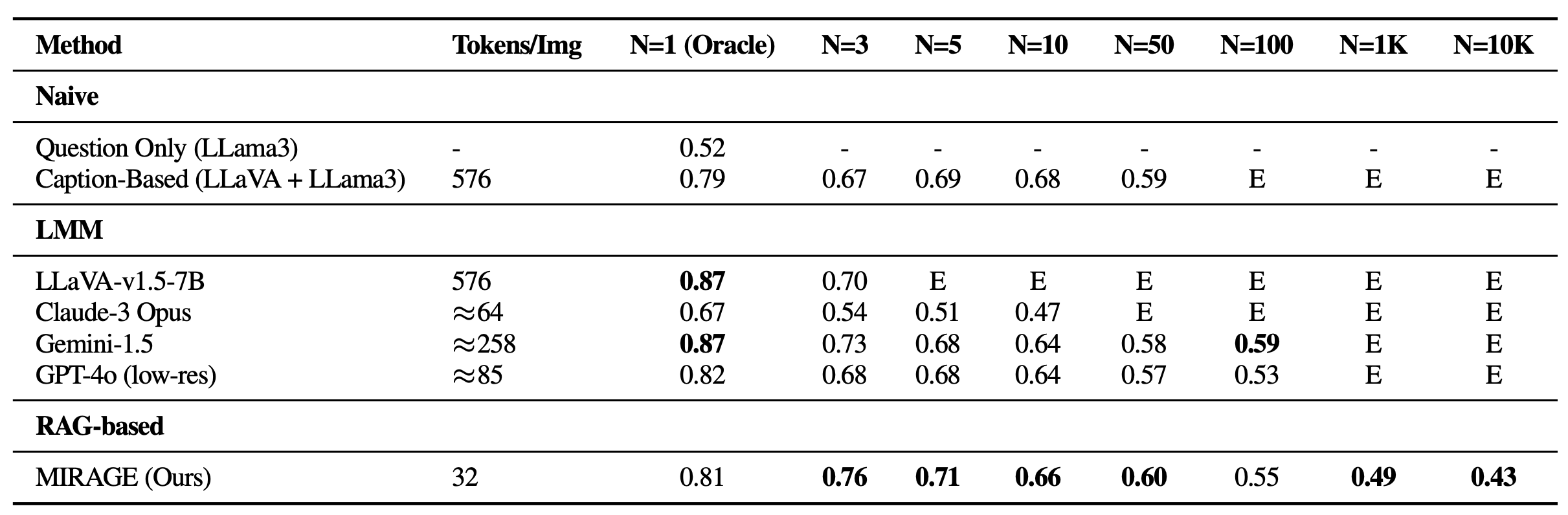
We additionally benchmark MIRAGE and different LMM-based fashions on quite a lot of VQA duties. On multi-image duties, MIRAGE demonstrates sturdy recall and precision capabilities, considerably outperforming sturdy rivals like GPT-4, Gemini-v1.5, and the Massive World Mannequin (LWM). Moreover, it exhibits aggressive single-image QA efficiency.
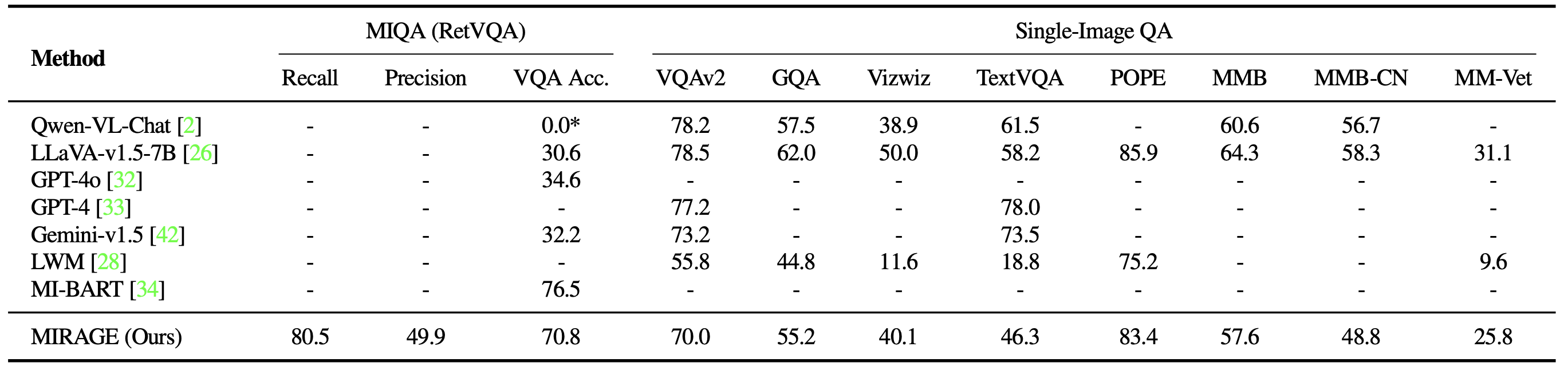
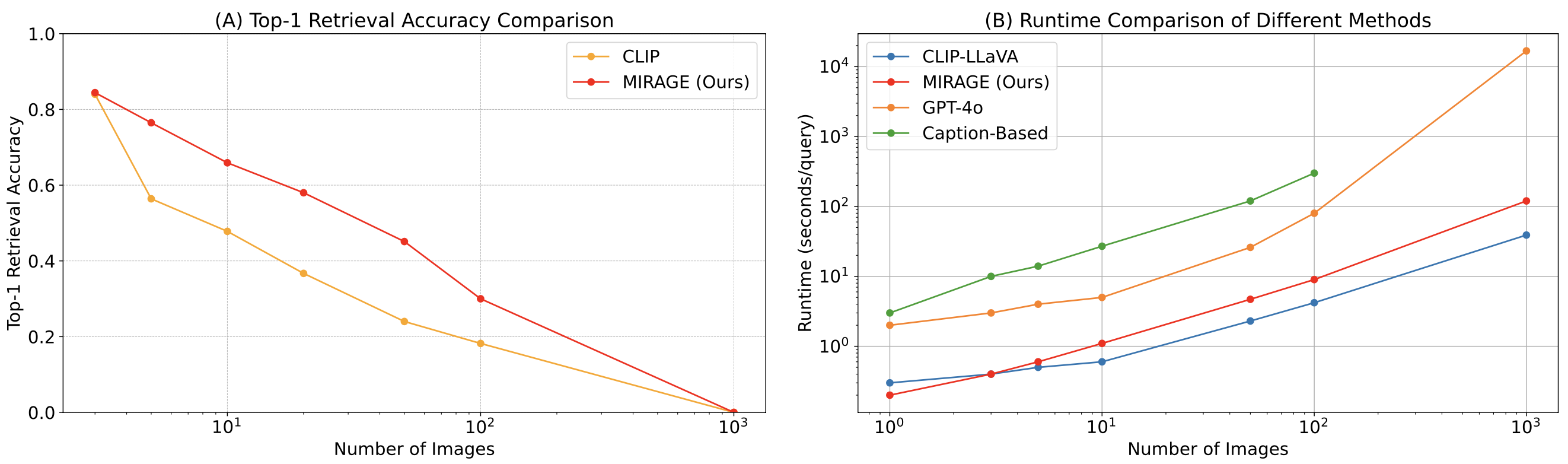
Lastly, we examine MIRAGE’s co-trained retriever with CLIP. Our retriever performs considerably higher than CLIP with out dropping effectivity. This exhibits that whereas CLIP fashions might be good retrievers for open-vocabulary picture retrieval, they might not work nicely when coping with question-like texts!
On this work, we develop the Visible Haystacks (VHs) benchmark and recognized three prevalent deficiencies in present Massive Multimodal Fashions (LMMs):
-
Struggles with Visible Distractors: In single-needle duties, LMMs exhibit a pointy efficiency decline because the variety of photographs will increase, indicating a big problem in filtering out irrelevant visible info.
-
Problem Reasoning Throughout A number of Photographs: In multi-needle settings, simplistic approaches like captioning adopted by language-based QA outperform all present LMMs, highlighting LMMs’ insufficient capacity to course of info throughout a number of photographs.
-
Phenomena in Visible Area: Each proprietary and open-source fashions show sensitivity to the place of the needle info inside picture sequences, exhibiting a “loss-in-the-middle” phenomenon within the visible area.
In response, we suggest MIRAGE, a pioneering visible Retriever-Augmented Generator (visual-RAG) framework. MIRAGE addresses these challenges with an progressive visible token compressor, a co-trained retriever, and augmented multi-image instruction tuning knowledge.
After exploring this weblog submit, we encourage all future LMM initiatives to benchmark their fashions utilizing the Visible Haystacks framework to establish and rectify potential deficiencies earlier than deployment. We additionally urge the neighborhood to discover multi-image query answering as a way to advance the frontiers of true Synthetic Basic Intelligence (AGI).
Final however not least, please try our challenge web page, and arxiv paper, and click on the star button in our github repo!
@article{wu2024visual,
title={Visible Haystacks: Answering More durable Questions About Units of Photographs},
creator={Wu, Tsung-Han and Biamby, Giscard and and Quenum, Jerome and Gupta, Ritwik and Gonzalez, Joseph E and Darrell, Trevor and Chan, David M},
journal={arXiv preprint arXiv:2407.13766},
yr={2024}
}